
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 로봇청소기
- 백준 14888번
- chromeSetup.exe 안됨
- 크롬설치
- 크롬 설치 안됨
- 연산자 끼워넣기
- ChromeStandaloneSetup64안됨
- chromeSetup.exe꺼짐
- 백준 14503번
- 바로꺼짐
- 삼성 sw 역량테스트
- 크롬설치파일꺼짐
- C++
- Today
- Total
공대생의 개발 일기장
인공지능 활용 4주차(K-Nearest Neighbor) 본문
깊은 개념에 대한 부분은 따로 서술하지 않겠다. 이 글에서는 간단하게만 그 주의 실습 내용에 대해서 요약이 되어있다.
먼저, numpy라이브러리를 이용해 평균과 표준편차를 구하는 방법이다.
mean = np.mean(train_input, axis = 0) # 열별 평균값 구함. -> [ ??, ??, ??, 4번째 열 평균]
std = np.std(train_input, axis = 0) # 열별 표준편차 구함.
이를 숙지하고 K-NN에 대해서 보자.
간단하게 말해서 K-NN은 지도학습의 하나로 '데이터 간의 거리를 기반으로 가까운 이웃 데이터의 클래스로 분류하는 알고리즘'이다. 자세한 부분은 구글링이든 뭐든 찾아보길 바란다. 한마디로 이웃에 따라서 데이터를 분류한다는 것.
Overfitting(과적합)과 Underfitting에 대해서도 보자.
Overfitting의 경우 모델이 학습 데이터에 매우 적합한 것인데 학습 데이터에서 매우 높은 정확도를 보이지만 새로운 데이터에 대한 일반화 성능이 매우 떨어진다. 반대로 Underfitting은 모델이 학습 데이터에 부적합한 것으로 정확도도 떨어지고 일반화 성능도 떨어지는 것을 말한다.
K-NN의 경우 '변수의 개수'에 따라 데이터 분류의 형태가 재밌어진다. 예를 들어 변수가 1개라면 수평면 위에서 변수가 2개라면 좌표 평면 상에서 데이터가 찍히는 것이다. 데이터 분류는 K-NN의 철학상 이러한 공간 위에서 "국소적인" 점들을 이용해서 추정하게 되는데 '차원의 저주'라고 해서 고정된 크기의 데이터들이 차원이 증가하면 할수록 데이터 공간이 점점 희박해지는 문제를 직면하게 되는 경우가 있다. 즉, 변수개수가 너무 많아지면(차원이 증가하면) 거리가 너무 멀어져서 잘 작동하지 않는 것이다. K-NN은 고차원 데이터셋에서 잘 작동하지 않는다.
여기까지 이론적인 부분을 봤고, 코드로 한번 살펴보자.
그전에 3주차에서 데이터를 분석하기 위해 배열을 조작했던 방법들 중에는 조금 더 쉽게 가능한 것들이 있다. 먼저, zip() 함수로 자료의 데이터를 하나씩 리스트로 구성했는데 더 쉬운 방법이 있다.
np.column_stack(([1,2,3], [4,5,6])) # 전달받은 리스트를 일렬로 세우고 연결
->
array([[1, 4],
[2, 5],
[3, 6]])
이를 이용해
fish_data = np.column_stack((fish_length, fish_weight))하면 3주차 zip()함수를 이용한 것과 같은 결과가 나온다.또, target 배열 (1과 0으로 이루어진)을 만들 때 3주차에서 썼던 방법말고
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
# concatenate함수는 두 배열을 연결해줌.이런 방법도 있다. 제일 복잡했던 TrainingSet과 TestSet를 랜덤한 index에 대해서 적절하게 섞는 코드도
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
# 기존코드
->
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, random_state=42)
# train_test_split 함수는 전달되는 리스트나 배열을 비율에 맞게 Training, Test 세트로 나누어 준다.
# 또한 나누기 전에 알아서 섞어주기까지 한다!
# fish_data -> train, test_input으로 fish_target -> train, test_target으로 나뉘어 4개 배열이 된다.
# random_state는 seed값으로 이를 42로 고정하면 무작위지만 항상 같은 결과가 나온다.당연히 샘플링 편향이 이렇게 나눠줘도 나타날 수도 있다. 이를 해결하기 위해 간단하게 train_test_split( )함수에 인자만 하나 더 추가하면 된다.
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42)
# stratify=fish_target가 추가되었다. stratify는 target 데이터를 전달하면 클래스 비율에 맞게 알아서 데이터를 나눠준다.
이제 K-NN에 대해서 살펴보자. 코드를 통해서 살펴보는 것이 이해가 더 빠를 것이다.
# K-NN training
from sklearn.neighbors import KNeighborsClassifier # sklearn.neighbors 라이브러리의 KNeighbors~클래스 사용
kn = KNeighborsClassifier() # 클래스 객체 생성
kn.fit(train_input, train_target) # fit() 메서드는 입력된 학습 데이터에 대해 모델을 학습
kn.score(test_input, test_target) # score() 메서드는 모델의 예측 정확도를 반환한다. (0~1 사이의 실수값으로)여기서 score를 적용했을 때 반환 값이 0.5면 말그대로 절반만 맞췄다는 것이다!
만약 score의 반환 값이 1.0이다. 즉, 100% 맞췄다고 한다면 새로운 test_input에 대해서
kn.predict(test_input) # predict()는 새로운 데이터의 정답을 예측한다.
kn.predict(test_input) = 1(도미) or 0(빙어) # score가 1.0이므로 무조건 맞춰야 한다.
그런데 새로운 데이터를 넣고 결과를 확인해보면 값이 다른 경우가 있다. 예를 들어 도미에 대한 데이터
를 넣었다고 가정하자.
kn.predict(도미 데이터) = 1 이여야 하는데 = 0을 출력할 때가 있다.3주차의 코드로 산점도를 그려보면 이해가 좀 더 쉬워진다.
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^') # marker 매개변수는 모양을 지정합니다. 주황색 세모
plt.ylabel('weight')
plt.show()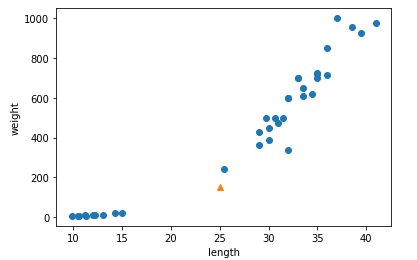
K-NN의 이론에 따르면 이건 분명히 (포스팅에는 도미와 빙어 데이터를 안적어 넣었지만) 왼쪽의 점들 모임보다는 오른쪽의 우상향의 점들의 모임과 가깝다. 이것은 도미이다. 그렇다면 당연히 주황색 세모에 대한 K-NN은 도미가 나와야하는데.. kn.predict(주황색 세모)로 넣어 확인해보면 왼쪽의 점들의 모임을 가리키는 빙어가 나온다. 엥? 왜지? 이해가 안된다.
자세한 추론 과정은 강의노트를 보면되고 결론을 얘기하면 x와 y축의 그래프 상의 범위가 달라서 지금 산점도 그래프 상의 우리 눈으로 보았을 때는 어? 도미가 더 가깝네? 하지만 데이터가 이해하는 것은 아닌 것이다. 범위를 똑같이 해서 보면 좀 더 명확해진다.
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D') # 이웃데이터 추가하는 것은 강의에서!
plt.xlim((0, 1000)) # x축의 범위를 0~1000으로
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
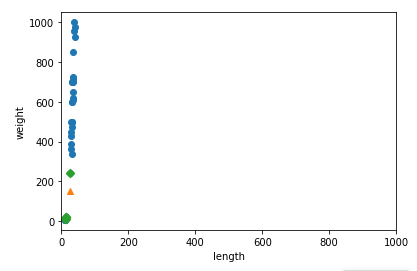
이젠 알겠지만 너무 명확해진다! x값이 결과에 영향을 전혀 주지 않는다. 이런 데이터 형태이기 때문에 predict()의 결과가 빙어가 나오는 것이다.
근데, 지금은 length와 weight지만 만약에 변수가 더 늘어나거나 혹은 차이가 더 명확한 변수를 사용한다면 어떻게 될까..?? 데이터를 표현하는게 더 어려워질 것이다. 즉, 정확한 예측이 힘들어질 것이다. 그러기 위해서는 어떻게 해야할까? 사실 답을 이미 알고 있다. 고등학교 수학에서 정규분포화 시키는 것처럼 우리도 똑같이 해줄 것이다. 이걸 데이터 전처리(data preprocessing)이라고 한다. (사실 정규분포화처럼 계산하는 것은 전처리 방법 중 하나이다. 근데 내가 익숙하면 좋지 뭐... 코드는 포스팅 맨 앞에서 사용했던 코드로 정규화 한다.)
그럼 이제 모든 데이터를 이렇게 전처리를 하고 K-NN을 해보자.
new = ([25, 150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
# K-NN training
from sklearn.neighbors import KNeighborsClassifier # sklearn.neighbors 라이브러리의 KNeighbors~클래스 사용
kn = KNeighborsClassifier() # 클래스 객체 생성
kn.fit(train_input, train_target) # fit() 메서드는 입력된 학습 데이터에 대해 모델을 학습
kn.score(test_input, test_target) # score() 메서드는 모델의 예측 정확도를 반환한다. (0~1 사이의 실수값으로)
->
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std # 정규화? 데이터 전처리!
kn.score(test_scaled, test_target) # 이건 같은 1.0으로 같은 결과가 출력된다.이제 kn.predict(도미 데이터)를 한다면? 이제는 값이 1로 정확하게 예측된 결과가 출력된다!
정리하자면 그냥 K-NN 모델 학습 전에 데이터 전처리를 꼭 해야한다~
Overfitting과 Underfitting에 대한 부분은 강의노트에서 확인해보자.
*이 글은 내가 나중에 보려고 작성하는 글이다. 남한테 도움은 안된다.
'Python & 인공지능' 카테고리의 다른 글
| 인공지능 활용 - 6주차(Stochastic Gradient Descent) (0) | 2023.05.04 |
|---|---|
| 인공지능 활용 - 5주차(Regression) (0) | 2023.05.04 |
| 인공지능 활용 - 3주차(Numpy, matplotlib) (0) | 2023.05.03 |
| 인공지능 활용 - 2 주차 (0) | 2023.05.03 |
| 인공지능 활용 - 1주차 (0) | 2023.05.03 |

